This post is intentionally long because it focuses on design constraints, not just APIs. These are the kinds of constraints that routinely trip up even experienced C++ developers.
VST3 development has more in common with embedded C/C++ than typical desktop software: tight timing budgets, strict threading rules, and zero tolerance for unbounded behavior. That's the lens we'll use throughout this post.
Overview
In VST3, the Controller and Processor communicate via host-mediated message passing (typically IMessage over IConnectionPoint). They can't reliably share memory, they're often on different threads, and sometimes even in different processes.
So the question becomes:
How do we move data between them without spamming the host or stalling real-time audio?
Rules
-
Do not spam
- Hosts are free to throttle, batch, queue, delay, or drop messages.
- If we push unbounded traffic, we'll eventually hit a host-specific cliff.
-
Do NOT block the audio thread
- If the Processor sends a message during
process(), assume we're on or adjacent to a real-time thread. - On the Controller side, assume
notify()might execute in a time-sensitive context too. - Treat message handling like a real-time callback: do the minimum work necessary and get out!
- If the Processor sends a message during
-
Do not try to "work around" the model
- Do not rely on "it's just a pointer between Controller and Processor."
- Do not rely on shared memory, memory mapping, or "clever IPC."
- We must design as if Controller and Processor can be isolated (thread/process).
Definitions
Before diving in, here are a few terms that come up often in real-time plugin development and message-passing systems. If you already know these, feel free to skip ahead.
1. Bounded
A bounded system has a known, fixed upper limit on how much data it can hold or process.
Examples:
- "This buffer can hold at most 1024 MIDI events per frame."
- "This queue drops new messages once it reaches capacity."
Bounded designs are essential in real-time systems because they:
- prevent unbounded memory growth
- make worst-case performance predictable
- avoid surprise allocations on time-critical threads
In VST3, anything touching the audio or message-handling path should be bounded by design.
2. Unbounded
An unbounded system has no fixed upper limit on size or growth.
Examples:
- Appending to a
std::vectorwithout a maximum - Logging every event indefinitely
- Dynamically allocating memory based on input rate
Unbounded designs are fine on background threads, but dangerous in real-time contexts. In a plugin, unbounded growth can:
- trigger allocations at the wrong time
- stall the audio thread
- cause hosts to disable or crash the plugin
3. Data Alignment
Data alignment refers to how values are laid out in memory relative to their size.
For example:
- a
floattypically expects to be stored at an address divisible by 4 - misaligned access may still work, but can be slower or unsafe on some platforms
Compilers often insert padding into structs to preserve alignment. That's why:
struct A
{
uint8_t a;
float b;
};
is usually 8 bytes, not 5.
Alignment matters because:
- misaligned loads can degrade performance
- packed structs can break ABI assumptions
- incorrect assumptions about layout can cause subtle bugs
For message passing, it's usually safer to serialize explicitly than rely on struct layout.
4. Real-Time (RT) Thread
A real-time thread is one that must complete its work within a strict time budget, typically without blocking or allocating memory.
In VST3:
- the audio
process()callback is real-time - code called indirectly from it (or from host messaging) should be treated as real-time sensitive
On RT threads:
- no blocking
- no locks
- no dynamic allocation
- minimal work only
Violating these rules leads to glitches, dropouts, or host instability.
5. High-Water Mark
A high-water mark is a threshold indicating when a buffer or queue is "too full."
Common strategies when the high-water mark is reached:
- drop new data
- drop old data
- coalesce multiple messages into one
- stop sending until the buffer drains
High-water marks are a deliberate design choice. They let us fail predictably instead of catastrophically.
6. Producer / Consumer
A producer/consumer model describes two roles:
- Producer: generates data (e.g., Processor sending MIDI events)
- Consumer: processes data (e.g., Controller UI rendering them)
In multi-threaded systems:
- producers and consumers often run on different threads
- communication must be synchronized carefully
- the producer should never wait on the consumer in real-time code
This model shows up repeatedly in VST3 plugin architecture.
Structure Creation & Data Layout
Let's define a simple MIDI event payload we'll use throughout:
struct Midi_t
{
uint8_t channel { 0 }; // 0..15
uint8_t pitch { 0 }; // 0..127
float velocity { 0.f }; // 0..1
};
On most modern ABIs, that struct becomes 8 bytes, not 6, because the compiler inserts padding to keep float aligned:
| Field | Size | Offset |
|---|---|---|
| channel | 1 | 0 |
| pitch | 1 | 1 |
| padding | 2 | 2-3 |
| velocity | 4 | 4-7 |
Don't "fix" this with #pragma pack(1)
#pragma pack(push, 1)
struct Midi_t { ... };
#pragma pack(pop)
Packing is tempting (esp. since we can ensure 6 bytes instead of 8), but it's usually the wrong trade:
- packed structs invite misaligned loads
- they can be slower (and on some platforms, fault-prone)
- they make ABI assumptions easy to break later
Instead, treat message payloads as byte buffers and serialize explicitly.
If you truly want a tiny MIDI payload, store normalized fields. Have a look at this little guy now:
struct MidiPacked_t
{
uint8_t channel; // 0..15
uint8_t pitch; // 0..127
uint8_t vel01_u8; // 0..255 (maps to 0..1)
};
static_assert( sizeof( MidiPacked_t ) == 3 );
Convert at the boundary (i.e., before sending and after receiving):
- send:
vel01_u8 = uint8_t(clamp(v01,0,1) * 255) - receive:
v01 = vel01_u8 / 255.f
Small Messages: Single-Event Queue (Great Default)
For small or infrequent messages, a simple producer/consumer queue is hard to beat.
Important detail: IConnectionPoint::notify() can run in a time-sensitive context. Don't allocate. Don't block. Don't log spam. Copy data and enqueue.
Controller side:
I use moody camel for portability. You can check it out at: https://github.com/cameron314/concurrentqueue
#include <concurrentqueue/concurrentqueue.h>
moodycamel::ConcurrentQueue< MidiPacked_t > m_queue;
// this can come in on the Processor's thread, e.g., the way Reaper does it
tresult PLUGIN_API Controller::notify( Steinberg::Vst::IMessage * message )
{
// Treat this as RT-sensitive: minimal work.
if ( !message ) return Steinberg::kInvalidArgument;
if ( Steinberg::FIDStringsEqual( message->getMessageID(), "midiId" ) )
{
const void * ptr = nullptr;
Steinberg::uint32 sz = 0;
if ( message->getAttributes()->getBinary( "midiAttr", ptr, sz ) ==
Steinberg::kResultOk &&
sz == sizeof( MidiPacked_t ) )
{
MidiPacked_t e;
std::memcpy( &e, ptr, sizeof( e ) ); // safe regardless of alignment
m_queue.enqueue( e );
}
}
return Steinberg::kResultOk;
}
UI Thread Side:
void Controller::consumeMidiEvents()
{
MidiPacked_t e {};
while ( m_queue.try_dequeue( e ) )
{
const auto v01 = static_cast< float >(e.vel01_u8) / 255.f;
doSomething( e.channel, e.pitch, v01 );
}
}
Bulk Messages: Don't Stream Events Through notify()
As an example, if we're inspecting all MIDI traffic (passthrough, multi-track scenarios, heavy automation), a per-event notify() call becomes:
- host spam
- unpredictable latency
- potential audio thread blowups
Instead, treat bulk transfer as snapshot + handoff:
- the Processor accumulates a batch locally (bounded)
- occasionally sends one message that contains a packed batch
- the Controller copies it into a staging buffer
- the UI consumes it on its own cadence
Design goals
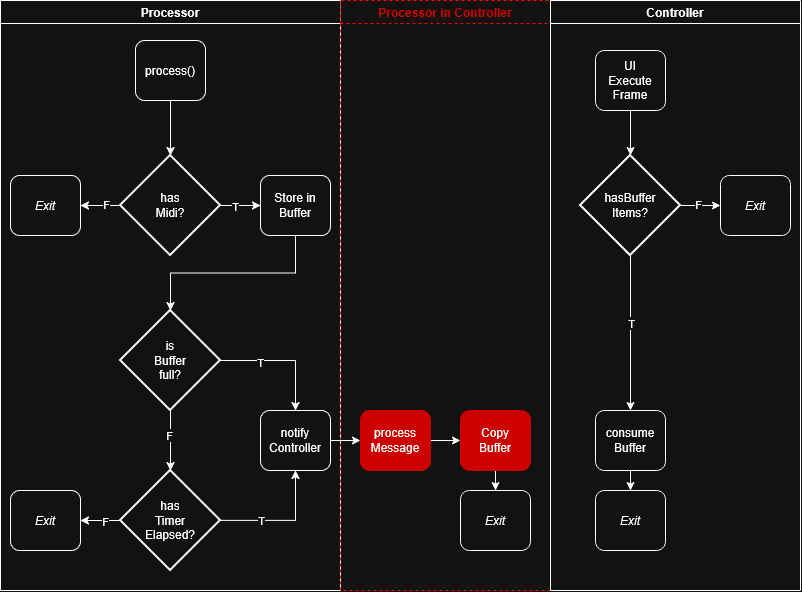
- time-sensitive and bounded
- has a high-water mark (drop policy)
- minimizes host messaging
A Correct Double-Buffer Snapshot (No Data Races)
The key: we can't write to a std::vector from a possibly RT context and "swap later" without risking:
- allocations
- data races between threads
Use fixed-capacity buffers with an atomic handoff:
template < typename T, size_t Max >
class DoubleBufferSnapshot
{
public:
// Producer: copies into the back buffer (bounded, no allocation)
void write( const T * data, uint32_t count )
{
count = std::min< uint32_t >( count, Max );
const uint32_t back =
1u - m_frontIndex.load( std::memory_order_relaxed );
std::memcpy( m_buf[ back ].data(), data, count * sizeof( T ) );
m_count[ back ].store( count, std::memory_order_release );
// publish that a swap is available
m_swapReady.store( true, std::memory_order_release );
}
// Consumer: swap on UI thread
bool trySwap()
{
if ( !m_swapReady.exchange( false, std::memory_order_acq_rel ) )
return false;
const uint32_t back =
1u - m_frontIndex.load( std::memory_order_relaxed );
m_frontIndex.store( back, std::memory_order_release );
return true;
}
const T * data() const
{
const uint32_t front = m_frontIndex.load( std::memory_order_acquire );
return m_buf[ front ].data();
}
uint32_t size() const
{
const uint32_t front = m_frontIndex.load( std::memory_order_acquire );
return m_count[ front ].load( std::memory_order_acquire );
}
private:
std::array<T, Max> m_buf [ 2 ] { }; // front & back buffers
std::atomic<uint32_t> m_count[ 2 ] {0, 0}; // actual count of each buffer
std::atomic<uint32_t> m_frontIndex {0};
std::atomic<bool> m_swapReady {false};
};
Controller notify() side (copy from message payload into snapshot buffer):
void Controller::notify( Vst::IMessage * message )
{
// RT-sensitive: do not allocate!
const void * p = nullptr;
uint32_t sz = 0;
message->getAttributes()->getBinary( "midiBatch", p, sz );
const auto * hdr = static_cast< const MidiHeader_t* >( p );
const auto * buf =
reinterpret_cast< const MidiPacked_t* >(
static_cast< const uint8_t* >( p ) +
sizeof( MidiHeader_t ) );
m_snapshot.write( buf, hdr->count ); // BOUNDED copy
}
UI thread:
void Controller::executeUIFrame()
{
if ( m_snapshot.trySwap() )
{
const auto* buf = m_snapshot.data();
const uint32_t n = m_snapshot.size();
for ( uint32_t i = 0; i < n; ++i ) { /* consume */ }
}
}
This gives us:
- bounded work on the RT side
- no allocations
- no vector races
- explicit drop behavior via Max capacity
A Note on Dynamic-Sized Payloads
Everything discussed above assumes bounded payloads (i.e., either single events or batches with a known maximum size). That constraint is intentional.
Dynamic-sized payloads (where the size is unbounded or unpredictable at runtime) introduce additional challenges in a VST3 environment:
- Memory allocation becomes dangerous if it occurs on, or near, the audio thread
- Data races are easy to introduce when resizing containers across threads
- Backpressure and flow control become necessary to avoid unbounded growth
- Ownership and lifetime of dynamically allocated buffers must be explicit
There are valid strategies for handling dynamic payloads safely, including:
- fixed-capacity snapshots with variable counts
- preallocated block pools / arenas
- producer-side truncation or coalescing policies
- background worker handoff for truly unbounded data
However, these approaches add complexity and require careful reasoning about threading, memory ownership, and real-time constraints. Covering them properly would pull focus away from the core communication patterns discussed here.
For now, the key takeaway is this:
If data originates from the Processor or any audio-adjacent context, it should be treated as bounded by design.
More advanced strategies for dynamic payloads will be covered in a future post.
Conclusion
For Controller - Processor messaging, "works on my DAW" isn't good enough.
- small/infrequent updates: copy -> enqueue -> consume on UI thread
- heavy traffic: batch + snapshot + bounded copy + UI swap
- always treat
notify()as RT-sensitive - never assume ordering, timing, or delivery semantics across hosts
Hope you enjoyed this topic. I've been working on it for a while and (to me) it's one of the most exciting design discussions in VST3/embedded development to have. It's really something that is so hard to fix once your project has legs and starts to run away from you. If you want to design audio plugins, then don't skip this topic.