Terminology
In this post, a "Mesh" refers to a single renderable line segment (internally treated as an edge). Higher-level meshes are just emergent behavior from many lines.
A look ahead
Let's start off with where we're going first. Here's a gif demonstrating two mesh algorithms playing together. That's the place we need to get to (as efficiently as is reasonably possible).

It's much smoother in reality. Giphy downsampled it and reduced the frame count, but you get the idea.
Overview
The Mesh stage (previously called Modifier) is used for creating Curved Lines between particles. Depending on the selected algorithm, it can go bananas and create a full mesh network or you can stack meshes to create different colors of webs. It's really the dealer's choice. But the old system was a prototyped version that needed a complete overhaul. Let me paint you a picture and you'll see where things went wrong. Let's look at things from the top down: ChannelPipeline -> MeshPipeline -> MeshAlgorithms
void ChannelPipeline::render()
{
// RIGHT HERE! this guy smells bad, he looks bad, and he's just out
// here in space, floating by himself and allocating memory every frame.
vector< unique_ptr< Mesh > > meshCollection;
// ... create particles and other stuff ...
meshPipeline.applyMeshes( meshCollection ); // <-- we own this guy
// let RAII clean up our meshCollection for us and
// and then vector gets deallocates internally memory too.
}
void MeshPipeline::applyMeshes( vector<...>& meshCollection )
{
// loop through each IMeshAlgorithm that's active
for ( auto& meshAlgo : MeshAlgoCollection )
meshAlgo.applyMesh( meshCollection );
}
void MeshAlgoOne::applyMesh( vector<...>& meshCollection )
{
for ( const auto& particle : particles )
{
// create a line between particles
// another sign that something isn't right! every algorithm
// just does whatever it wants in terms of memory allocation.
meshCollection.push_back( make_unique< Mesh >( ... ) );
}
}
It was speedy to get up and running. The momentum was with me and I added several mesh algorithms in quick succession. The problem was that it could make thousands of small heap allocations and deletions in a single frame! We're talking fragmentation, cache misses, allocation latency. If we want to keep hitting our 16ms limit, then we better do something!
The Overhaul
Let's get a few things straight:
- No more heap allocations (from us)!
- our std containers will still allocate memory
- No running wild on container iterations!
- Minimal changes to the existing API and general flow (aka, the "be lazy" rule)
I've sketched out a design. Let's see how it works:
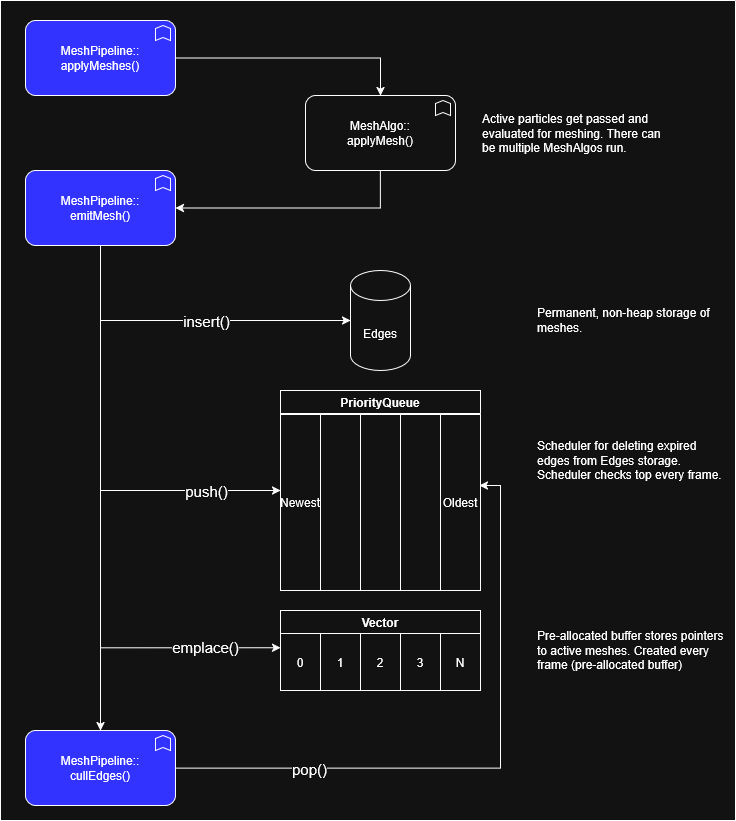
Your first thought might be that we made a tradeoff of space for time. And you'd be right. The other thing you might think is that we haven't really solved the cache adjacency issue. And again, you'd probably be right.
A short tangent on cache lines
For those not familiar, the CPU doesn't grab single addresses of data on modern architectures. It grabs cache lines. Let's say you ask for an integer (4 bytes on a 64-bit processor). The CPU checks its existing cache lines (i.e., L1 -> L2 -> L3). It's not there. It's not going waste cycles fetching 4 bytes. It'll grab 64 bytes or a cache line equivalent size that contains the address required.
In our circumstance, we can end up with something like the following, where Edges is an unordered_map< EdgeKey, Edge > and Vector is a vector< Edge* >;
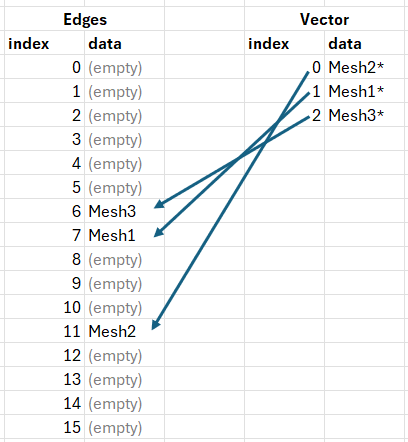
Iterating the pointer array itself is cache-friendly; dereferencing those pointers is where locality falls apart. The pointers in Vector will (most likely) all be part of a single cache line because 3 pointers on x64 is 24 bytes and on most modern x86 CPUs, cache lines are 64 bytes. Here's what that looks like:
Vector[ 0 ] iteration:
- L1 -> miss
- L2 -> miss
- L3 -> miss
- fetch from DRAM
- CPU gets cache line for Mesh2*
Vector[ 1 ] iteration:
- L1 -> hit (fetched)
Vector[ 2 ] iteration:
- L1 -> hit (fetched)
for ( auto * ptrEdge : Vector )
{
std::cout << ptrEdge->length;
}
The first ptrEdge might miss L1 cache. Afterwards, the remaining L1 hits are ideal. Dereferencing ptrEdge and getting length might look like this:
ptrEdge->length (Mesh2*): iteration
- L1 -> miss
- L2 -> miss
- L3 -> miss
- fetch from DRAM
- CPU gets cache line for Mesh2
ptrEdge->length (Mesh1*): iteration
- L1 -> miss
- L2 -> miss
- L3 -> miss
- fetch from DRAM
- CPU gets cache line for Mesh1
Cache efficiency depends on memory locality.
And that's a loose illustration of a cache miss and how we might fall into it more than we want to for a real-time GPU-driven VFX engine. But we're not gonna sweat it for now. Just be aware that the pros do sweat it.
Bottom-up: The Mesh Algorithms
These mesh algorithms are dumb as rocks and that's the way I like 'em. I don't want to go in and smarten them up one by one; that would be a violation of rule #3.
We can adjust our Mesh Algorithms with one very small refactor:
// DEPRECATED: stop using this!
virtual void applyMesh(
MeshContainer< unique_ptr< Mesh > >& outArtifacts ) = 0;
// Use this one instead now
virtual void applyMesh(
IMeshEmitter& meshEmitter ) = 0;
And now, any creation goes to our meshEmitter instead of creating an object on the heap.
// called and owned by MeshPipeline
void MeshAlgoOne::applyMesh( IMeshEmitter& meshEmitter )
{
// these come from the class's settings that are user adjustable
// and the bare minimum required for creating a line.
MeshMetaData metadata
{
.width = 1.f,
.curve = 0.25f,
.color = ...
// you get the idea
};
for ( const auto& particle : particles )
{
// create a line between particles
meshEmitter.emit( particle, otherParticle, metadata );
}
}
Top-down: The ChannelPipeline Downgrade
As much as we love executive management micromanaging us, we need to relieve ChannelPipeline of its duties and this is the simplest one of all.
// called by MultiChannelPipeline
void ChannelPipeline::render()
{
// ... create particles and some other stuff ...
const auto * meshes = meshPipeline.applyMeshes();
// meshes can be passed on to other components
}
That feels real good. The bad guy is gone.
Middle Management: The Mesh Pipeline Upgrade
With every promotion comes a new title. Our MeshPipline is now an IMeshEmitter.
// this is owned by the ChannelPipeline
class MeshPipeline final : public IMeshEmitter // <-- we're this now!
{
public:
// the interface IMeshEmitter only requires this one function
void emit( IParticle& a, IParticle& b, MeshMetaData& metadata ) override;
}
This is the rundown of what our callback should do.
// IMeshable (the Mesh Algorithms) calls this
void MeshPipeline::emit( IParticle& a, IParticle& b, MeshMetaData& metadata )
{
// 0. create the edge (make it look good!)
auto& mesh = createLine( a, b, metadata );
if ( m_edges.find( mesh ) == m_edges.end() )
{
// 1. insert the edge into Storage
// (don't get hung up on what meshState is)
m_edges.insert( { mesh, meshState } );
// 2. push the key & expiration time into the priority queue
m_expirySchedule.push( mesh );
}
// 3. add a pointer to the line into our vector for clients
// remember this m_clientVector for the snippet below
m_clientVector.push_back( &mesh );
}
And then that allows our applyMeshes() to be simplified:
// ChannelPipeline calls this
vector<const Mesh*>& MeshPipeline::applyMeshes()
{
// 1. clear the vector of the previous pointers
m_clientVector.clear();
// 2. go through all our loaded mesh algorithms
for ( const auto& modifier : m_modifiers )
{
// 2b. we pass ourselves now that we're a fancy IMeshEmitter
modifier->applyMesh( blendMode, particles, *this );
}
// 3. cull any lines at the end
cullExpiredEdges();
// 4. our clients ONLY get what's active
return m_clientVector;
}
And that takes us into the final change, which is deleting old lines that aren't in use.
void MeshPipeline::cullExpiredEdges()
{
// if we've reached an expiration time that is valid
// then we can stop because everything else is guaranteed
// to be younger
bool reachedLimit = false;
// what's the current time?
const auto currentTime = getTimeNow();
while ( !m_expirySchedule.empty() &&
!reachedLimit )
{
// grab the oldest item
const auto& top = m_expirySchedule.top();
// is the oldest item
// expiryTime is an absolute timestamp in seconds (float)
if ( top.expiryTime - currentTime <= 0.f )
{
const auto it = m_edges.find( top.edgeKey );
if ( it != m_edges.end() )
m_edges.erase( it );
else
{
// this is a big problem!
LOG_ERROR( "FAILED TO FIND ITERATOR!" );
assert( false );
}
m_expirySchedule.pop();
}
else
{
reachedLimit = true;
}
}
}
Conclusion
This was a lot of fun. We challenged our architecture and we challenged ourselves.
The Pros:
- The priority_queue gives O(log n) clean up time on every frame instead of O(n)
- We don't make anymore heap allocations for edges and they persist across frames!
- We guarantee the downstream stages that the edges we give them are active and correct
- We don't deal with any pointer instability (i.e., references to pointers we don't own that have data that could make our own data stale or null pointer dereferences)
As a follow-up to #4, meshes are stored in an unordered_map container with stable addresses for their entire lifetime (no reallocation or rehash invalidation), which guarantees that pointers handed to downstream systems remain valid until explicit expiration (i.e., stable for the duration of the frame).
The Cons:
- The aforementioned cache misses
- We didn't deal with duplicate lines from multiple mesh algorithms (in reality, I do allow for duplications, but I didn't want to muddy the water with more details.)
- We take up a lot more space now. Is this a big deal? I don't think so. I think ensuring we hit our time performance requirement is far more important.
- We've increased the complexity of the system, but hopefully not in an unintuitive way.