Architecture
A few things:
- I use SFML v3 for graphics and ImGui for the menus. SFML is a 2D graphics library written on top of OpenGL (while allowing us to interact directly with OpenGL).
- The current implementation of nyx.vfx limits the number of channels to 4, but it could be 16 or 32 or however many we want.
- It's imperative we deeply understand one simple rule: render on the same thread our textures are created on!
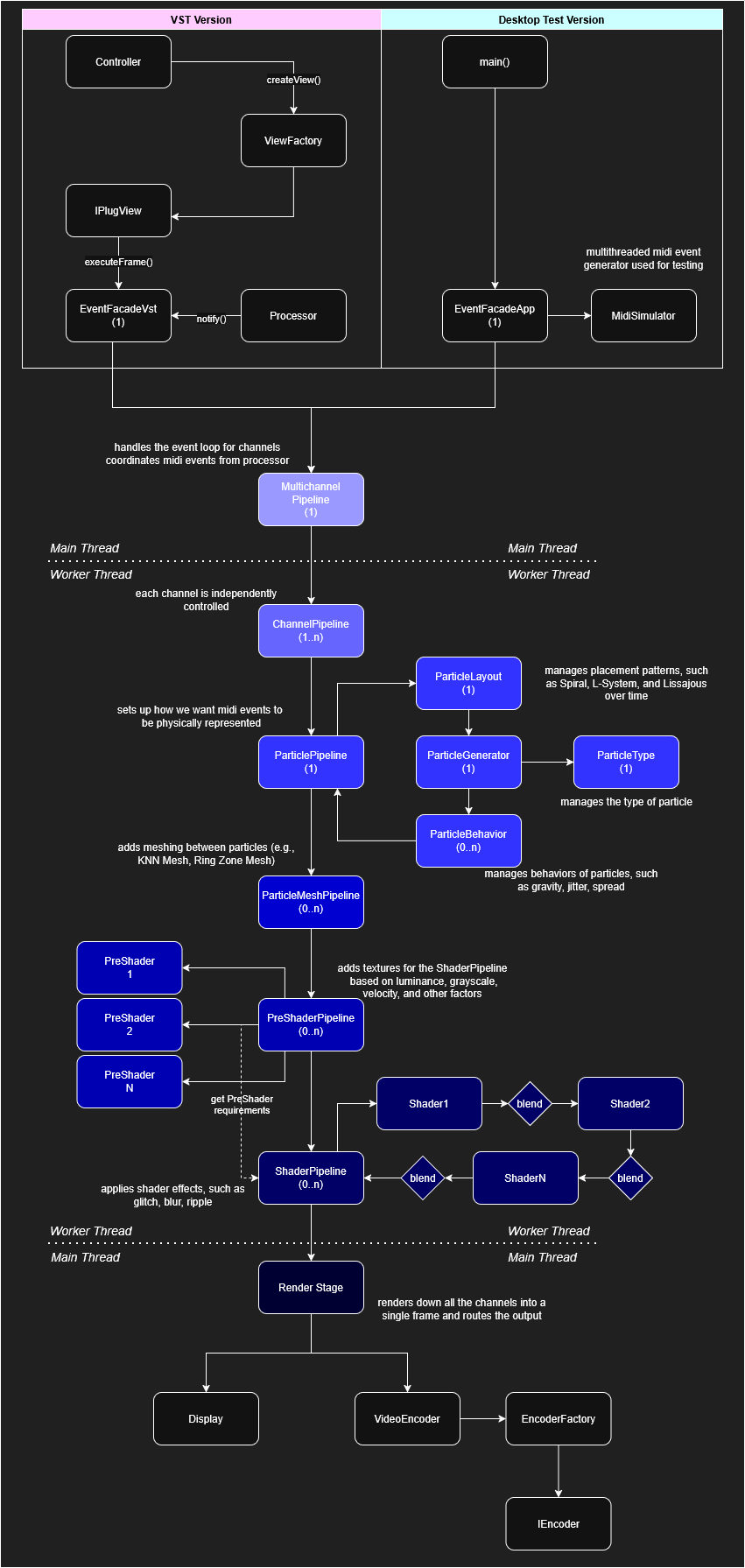
updated architecture diagram on 2025-12-31
The renderer is part of the MultichannelPipeline, so let's examine it a little closer:
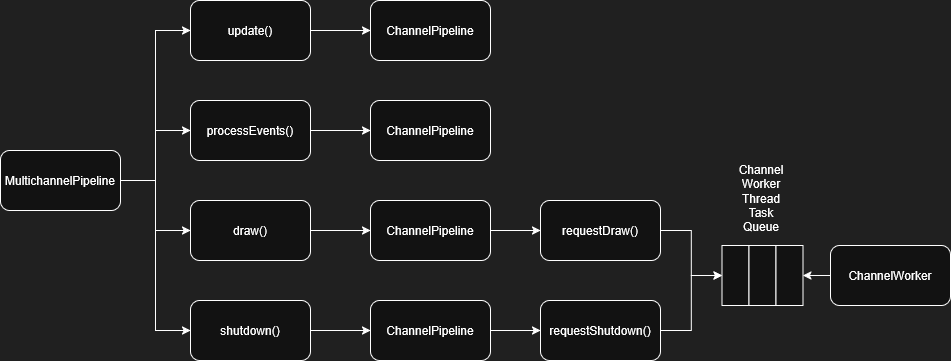
Architecturally, this is how we cleanly separate the threads. For every ChannelPipeline, there's a ChannelWorker that runs on a separate thread and runs tasks. We only need to move the rendering tasks on a different thread. But you may have noticed that the shutdown request also runs on a different thread.
That's because our texture MUST be initialized, rendered, and destroyed all from the same thread. Here's the flow and layout of our LazyTexture. For simplicity, I've whittled it down to the essentials:
class LazyTexture
{
public:
~LazyTexture() { /* do NOT release memory */ }
// do NOT use the destructor. use this instead!
void LazyTexture::destroy()
{
ensureOwner();
freeTextures();
}
void ensureSize(const sf::Vector2u &size)
{
ensureInitialized();
ensureOwner();
resizeIfNeeded();
}
void clear(const sf::Color &color)
{
ensureInitialized();
ensureOwner();
clearTexture(color);
}
void display()
{
ensureInitialized();
ensureOwner();
displayTexture();
}
[[nodiscard]]
const Texture& getTexture();
private:
void ensureInitialized()
{
// create unique_ptr to textures
if ( !isAllocated() )
{
// this is the lazy initialization.
// allocate your textures before using and
// set the thread id, so we can ensure we
// only operate on the textures from the same thread
allocateTextures();
m_ownerThreadId = std::this_thread::get_id();
}
}
void ensureOwner() const
{
// check that we're on the thread
assert(std::this_thread::get_id() != m_ownerThreadId)
}
};
And then in our MultichannelPipeline, we can issue a draw request to each ChannelWorker and it will render its content. At that point, we'll want to grab a pointer to each channel's final (i.e., fully rendered) texture and then draw that in its drawing order to our Window. Here's a condensed version of MultichannelPipeline's draw function:
// we want to prioritize render. we kick off the rendering
// process for each channel, but this is the order we'll
// render to our window or main texture
struct ChannelDrawingData_t
{
int32_t priority { 0 };
ChannelPipeline * channel { nullptr };
ChannelWorker * channelWorker { nullptr };
// Overload '<' for std::priority_queue (max-heap)
// Lower priority value = higher actual priority
bool operator<(const ChannelDrawingData_t& other) const
{
return priority > other.priority;
}
bool operator>(const ChannelDrawingData_t& other) const
{
return priority < other.priority;
}
};
void MultichannelPipeline::draw( sf::RenderWindow &window )
{
// add a render update request and then start all the channel pipelines
// this is where we actually tell each channel to start rendering
for ( int i = 0; i < m_channels.size(); ++i )
{
// skip the channel if it's bypassed
if ( m_channels[ i ]->isBypassed() ) continue;
// create the Task to update our channel's textures
m_channels[ i ]->requestRenderUpdate();
// notify that channel's thread that we need to
// to reset its state and run any incomplete tasks
m_channelWorkers[ i ]->requestPipelineRun();
// set up our drawing info in a priority queue
m_drawingPrioritizer.emplace( ChannelDrawingData_t
{
.priority = m_channels[ i ]->getDrawPriority(),
.channel = m_channels[ i ].get(),
.channelWorker = m_channelWorkers[ i ].get()
} );
}
// all the channels are currently rendering at this point
// we need to render each one's final texture to our
// window in a particular order
while ( !m_drawingPrioritizer.empty() )
{
// grab the top priority texture
const auto& top = m_drawingPrioritizer.top();
// if it's not finished, then we wait.
// we only need to wait on the one that takes the longest, e.g.,
// there are four channels and it takes the follow amount of time:
// 3ms, 5ms, 1ms, 1ms. then we only wait 5ms max rather than 3 + 5 + 1 + 1,
// because we'll wait 3ms on the first and then the remaining 2ms on the 2nd
// and then the last 2 will already be finished.
top.channelWorker->waitUntilComplete();
// get the final texture for the channel
const auto * texture = top.channel->getOutputTexture();
if ( texture != nullptr )
{
// render that final texture to the window
window.draw( sf::Sprite( texture->getTexture() ),
top.channel->getChannelBlendMode() );
}
// must pop no matter what or an infinite loop will occur
m_drawingPrioritizer.pop();
}
// if we want to record the frame for video encoding then we do that here
}